Update 2: Redesigning the classification software.
Intro
One thing I quickly realized while working on this project was how hard it actually is to accurately detect people through really dense foliage/lots of obstructions. My solution for this was to create a stack of models as opposed to a single generalized model to achieve better results.
The Stack
The stack consists of 11 primary models for classification/tracking, each of which as a specific task. The models are as follows (though note that the
order here doesn't really matter):
2. Outfit detection
3. Facial (IR)
4. Facial (RGB)
5. Feature detection
6. Gaze detection
7. Histogram of Oriented Gradients (in this case, checks that target is shaped like a human)
8. LiDAR
9. Vertical (top-down) human detection
10. Horizontal human detection
11. Weaponry detection
The stack itself is simply an instance of each model, ordered based on the weight each model has (based on model reliability in varying conditions.) It's a lot easier to use diagrams to explain this, so I've made a few (somewhat terrible) diagrams.

Model stack diagram. Copyright (c) Dylan Buchanan. All Rights Reserved.
The diagram above shows that stack, though is a bit useless on its own. The general idea here is just to establish the idea of the model stack as an object so that it'll make more sense later on.
The Setup
Now that you hopefully understand the model stack structure, let's move on to the rest of the setup. Individual frames (images) are placed
into a stack (the frame buffer) from the video stream. The frame buffer has the oldest frames on the bottom, while the newer ones are placed
on the top - it's a standard stack. A number of groups are created - anywhere from 8 to as many as your machine can handle - which are
responsible for processing any frames sent their way. Each group runs a model stack (not to be confused with an actual stack data structure,
or the frame buffer I just mentioned.)
This is the setup (the title of the diagram is slightly off since this particular one doesn't show the entire pipeline):
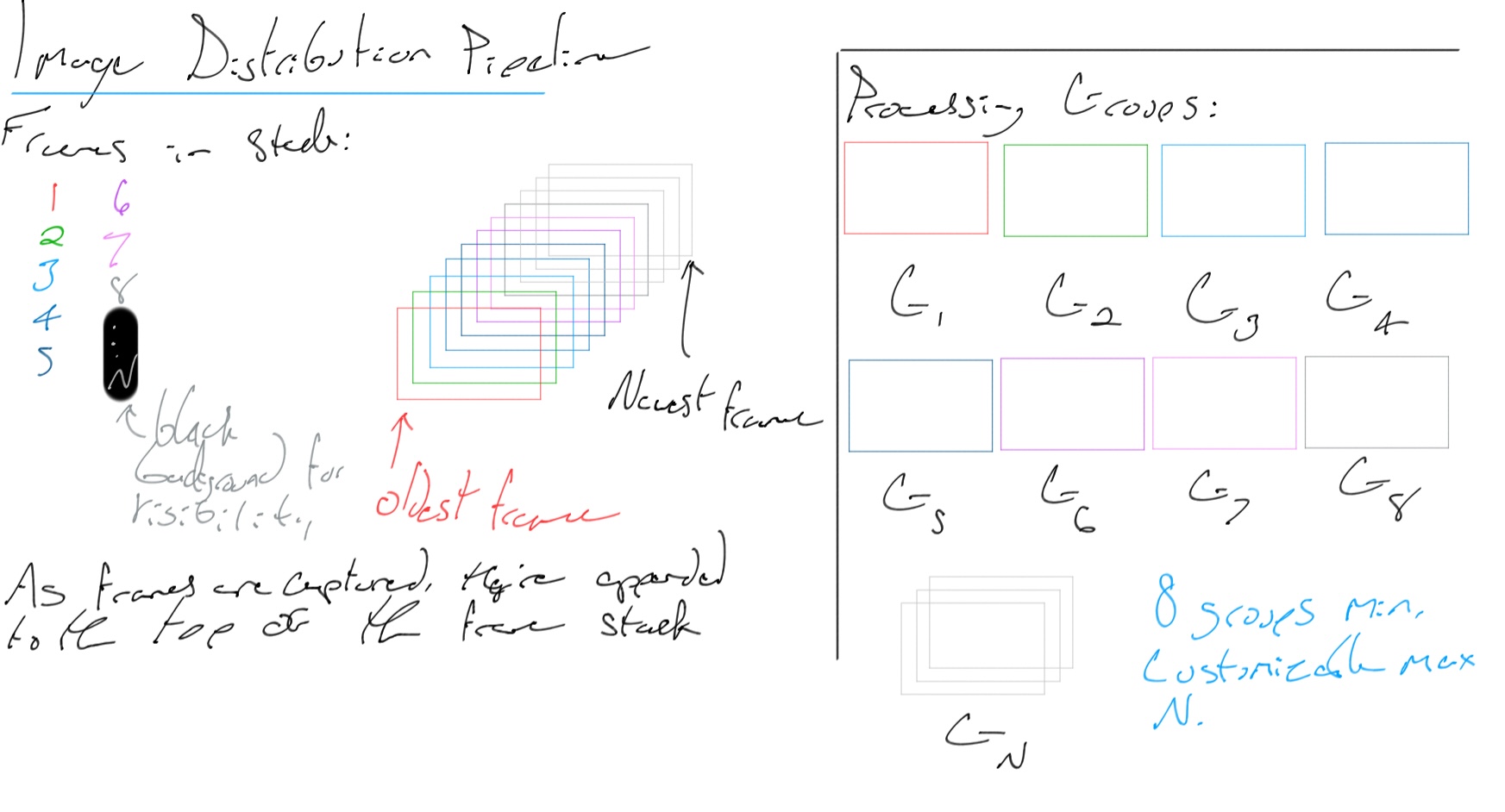
Frame distribution setup diagram. Copyright (c) Dylan Buchanan. All Rights Reserved.
Frames are actually distributed to the groups as shown below. After a batch of frames is sent out, the frame buffer contains N less frames (where N is the number of groups.)
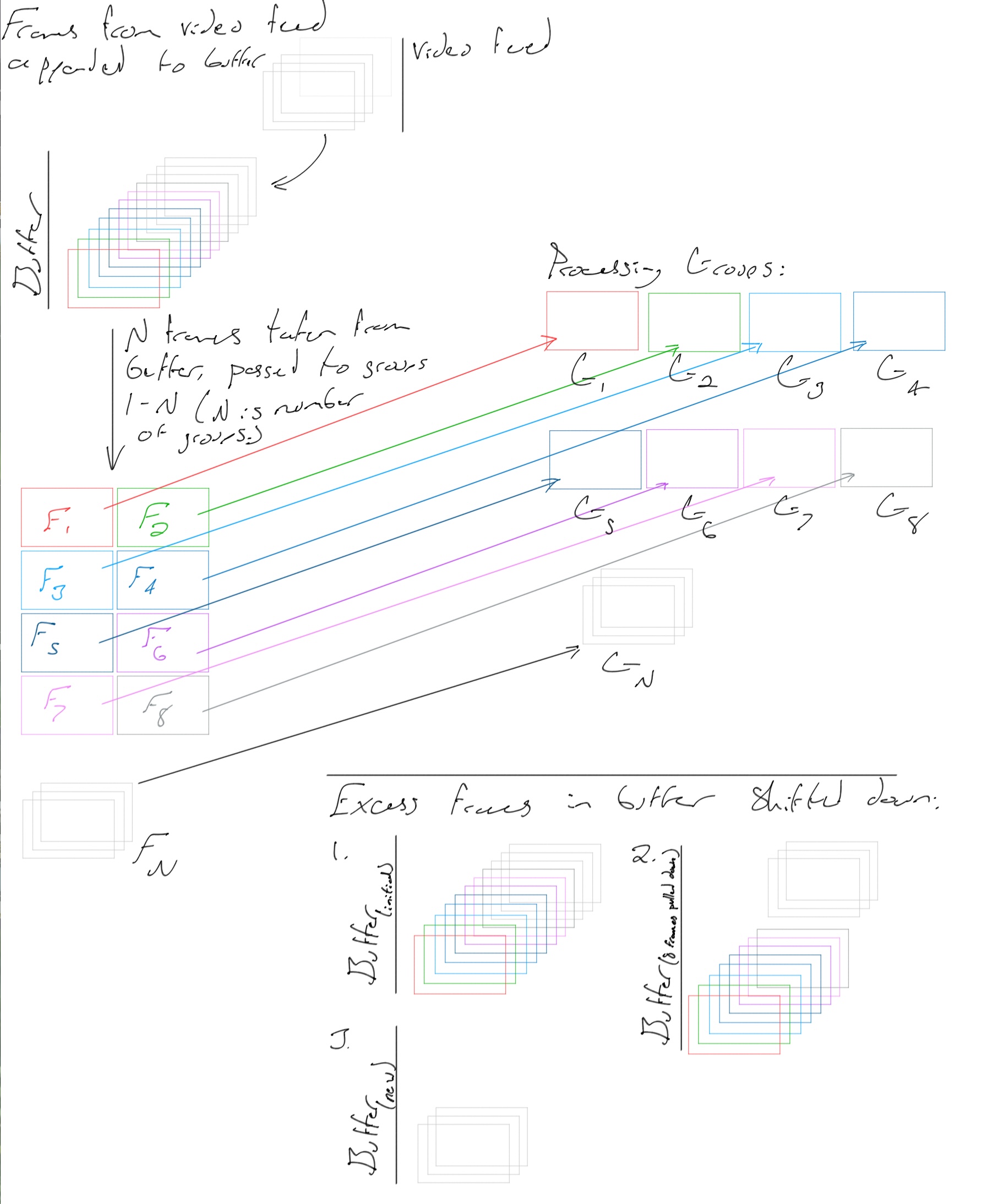
Frame distribution diagram. Copyright (c) Dylan Buchanan. All Rights Reserved.
And lastly, the diagram detailing the entire workflow from frame buffer to results.
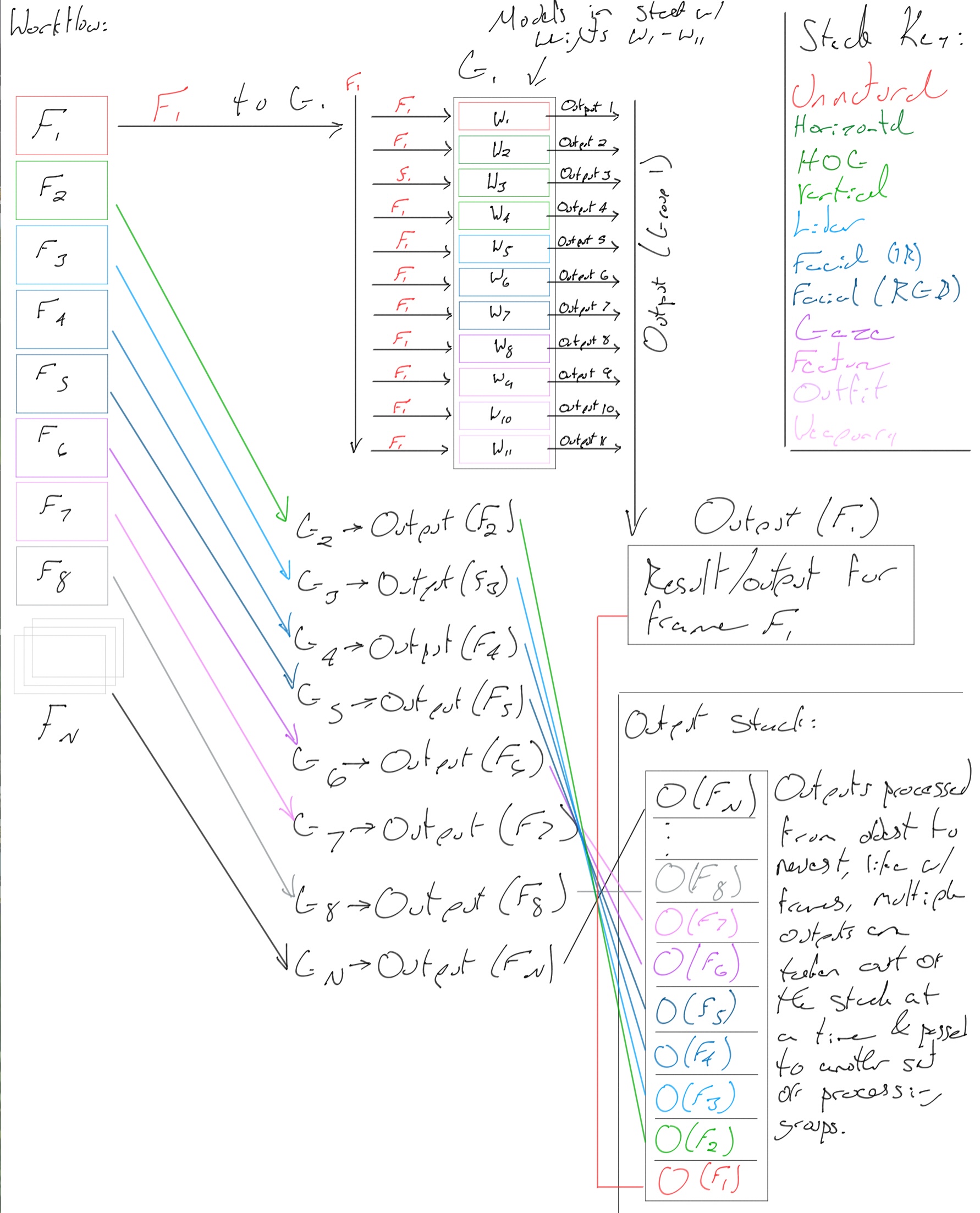
Overall workflow diagram. Copyright (c) Dylan Buchanan. All Rights Reserved.
One thing to note that I didn't bother trying to include in the diagrams is that there are two very important clocks that are running in the background throughout the classification process. The first tracks the rate at which frames are being classified (across all groups). The second tracks the rate at which results are being processed/instructions are being sent to the drone. If the classification rate falls behind the video frame rate, one of two things will happen:
b. Frames will be skipped to allow the current number of groups to have a classification rate equal to the partial frame rate. i.e. if the current classification rate = 10 fps & the native video frame rate is 60 fps, we should only look at every 1 in 6 frames since we can't add extra groups to compensate. This situation isn't ideal, but it's better than just getting farther and farther behind as frames continue to be captured at the video frame rate.
Summary
To summarize, the new system utilizes multithreading with a dynamic set of groups (each of which runs its own model stack) to make classification significantly more
efficient. Aside from making classification and autopilot/tracking generally more responsive, it significantly increases reliability since
processes will theoretically always be up to date, even if it means skipping a few frames here and there.
Of course it would be ideal to never have to skip frames
(more data is good) but skipping frames keeps us up to date if we can't keep up through sheer compute power alone. It's better to have a drone that's mostly sure
it's following/watching a person than to have a drone that is figuratively 10 steps behind the person, and will only catch up if they decide to stop (that is if it
manages to keep up that ten second delay - if falls further and further behind, it will reach a point at which it is unable to track the person because they've just
left.) Skipping frames is a last resort, but it's much better than the alternative.
The other massive benefit with the stack of models is that it
allows for significantly better (as in more accurate) results. Having each model look for a specific thing means that they can be trained more (longer)
than a generalized model that has a rough idea of what a person looks like.
I briefly want to point out that it's also really important to remember that with a
singular generalized model, our dataset would have to contain images from all sorts of angles with various obstructions, etc. Not only would it be massive, but it would also be
extremely difficult to ensure that it has sufficient diversity - it's a lot easier to get pictures of people standing upright in a variety of different surroundings/backgrounds
than from a bird's eye view, for example.
For a potentially more concrete example, having a set of models that each detect an attribute of a person also gives us greater
control of what the system actually "thinks" a person is: with a generalized model, for all we know a person only counts as a person if there's a bit of foliage covering at least
50% of them - which would be a requirement that would've stemmed from a strange trend in the dataset. Not only could it be really difficult to pick up on what this trend might be,
we'd have this same problem several times over given the difficulty of getting a dataset sufficiently diverse/varied for our model.
With this new stack-of-several-specialized-models-version,
we can effectively tell the system that a person is usually something that looks out of place in its surroundings (unnatural colors), has a general stick figure-like shape (effectively what the
HOG detector looks for), has a rough 3d shape as defined by the LiDAR dataset, etc. Overall, this approach provides far better results in all sorts of
conditions since there's always models to fall back on if the situation is particularly challenging, and if not, we can go through a more rigorous process
to decide whether or not the object in question is a person.
You may have also noticed models like the gaze or weapon detection ones. These are for target
tracking & threat assessment, respectively. While they're less accurate with more obstruction, (relatively speaking, all models are less accurate with more obstruction
between the drone and the target of course) they can still be super helpful in lots of situations.
Another thing to note is that model weights don't entirely
depend on their respective reliability, but also on their confidence for each frame. If an inaccurate model is super confident it sees a person, while it's important to
consider that it may actually be on to something, and we can take more steps to verify its claim. (It's still important to acknowledge that we know it can be unreliable, and should be treated as such.)
This secondary verification process is a bit complicated for a short overview here, so I'll probably go further into it in a future update. In essence, it uses a "decomposition" model that attempts to
process different parts of an image based on recent data (from the current task) as well as "knowledge" on what might be a promising region. Effectively feature localization, but a bit more complicated.
There's also support for thermal imaging when additional verification is needed, or as just another model that runs with the rest in the stack. Note that while thermal imaging-based feature localization
is absent from the above diagrams, it is still fully supported. The reason it is absent is because thermal imaging equipment can be expensive, and the system works without it. I do want to be very clear that it
is a better idea to use a thermal-imaging-capable drone for best results, see more about drone selection here.
I also wanted to briefly mention that
the reason for having the multithreaded groups that each run a stack is primarily out of necessity due to having a much more intensive classification process with multiple models, though it is a good idea in general
to get a faster overall classification rate.
